 Weblog Publishing Addin
Weblog Publishing Addin
 Weblog Publishing Addin
Weblog Publishing Addin
Markdown Monster supports publishing your Markdown content to various supported Weblog providers or tools. You can readily publish content from the active Markdown document to:
The publishing process lets you publish a Post from any Markdown document to a configured Weblog with a simple Publishing operation:
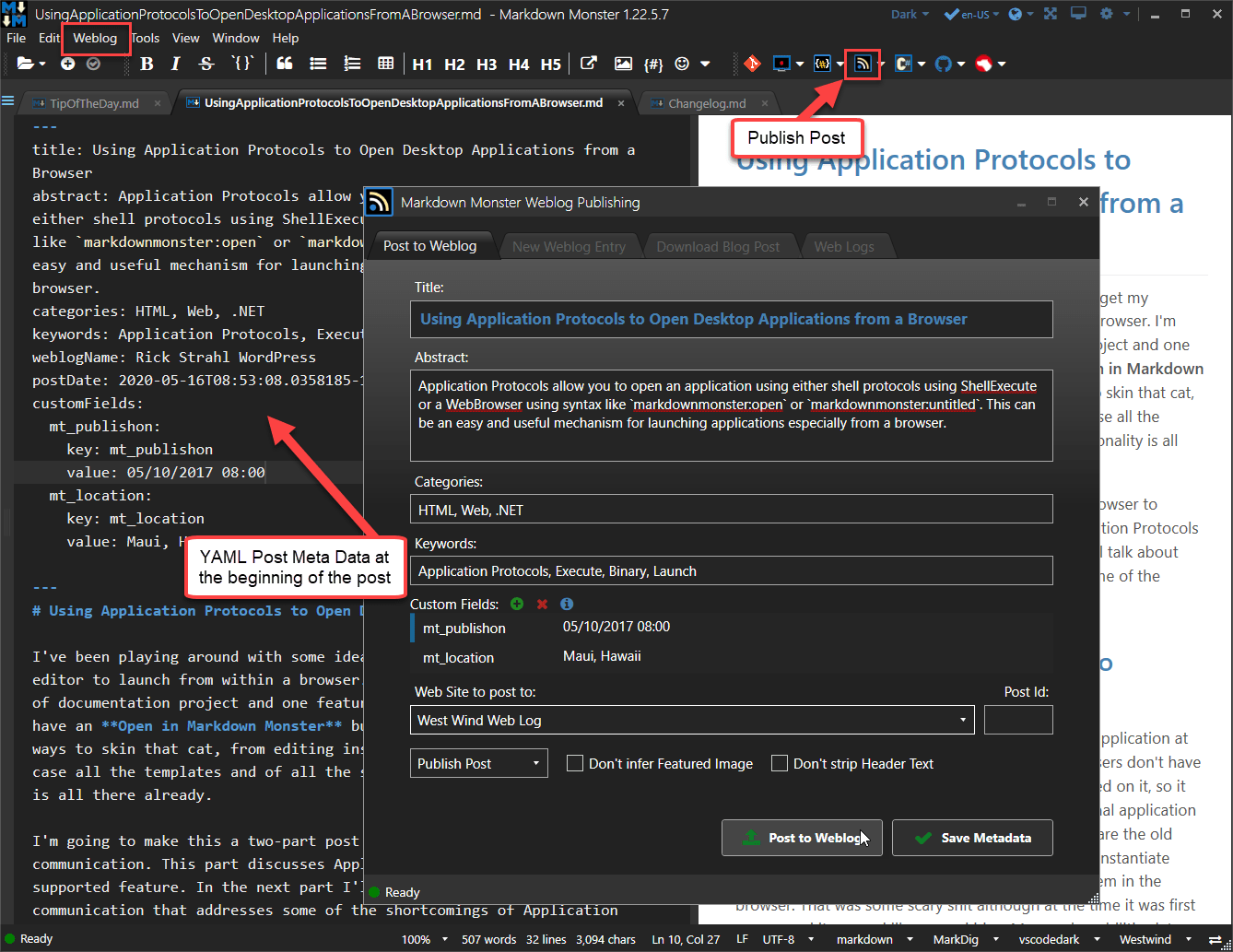
In order for this to work, you need to:
- Write your Markdown content
- Link any images from a relative folder or from online URLs
- Configure a Weblog Configuration
- Publish your post (alt-l-p)
The toolbar button or any of the menu options on the Weblog menu bar bring up the Weblog Publishing dialog which provides the following features:
- Posting to a Weblog
- Creating a new Blog Entry (creates new doc and folder)
- Downloading existing Posts
- Managing your Weblogs to publish to (add, edit, delete)
Create a Weblog Post
In Markdown Monster a blog post is simply a Markdown document with some associated YAML meta data. The YAML data doesn't have to exist in your document - but it is added or updated as part of the publishing process.
There are a few ways you can create a blog post:
- Create a new using New Weblog Post in MM
- Create a new blank document and just start writing
- Use any existing Markdown document
You can take any existing document and publish it as a Weblog post.
New Weblog Post
More formally - you can use the New Weblog Post dialog to create a Post.
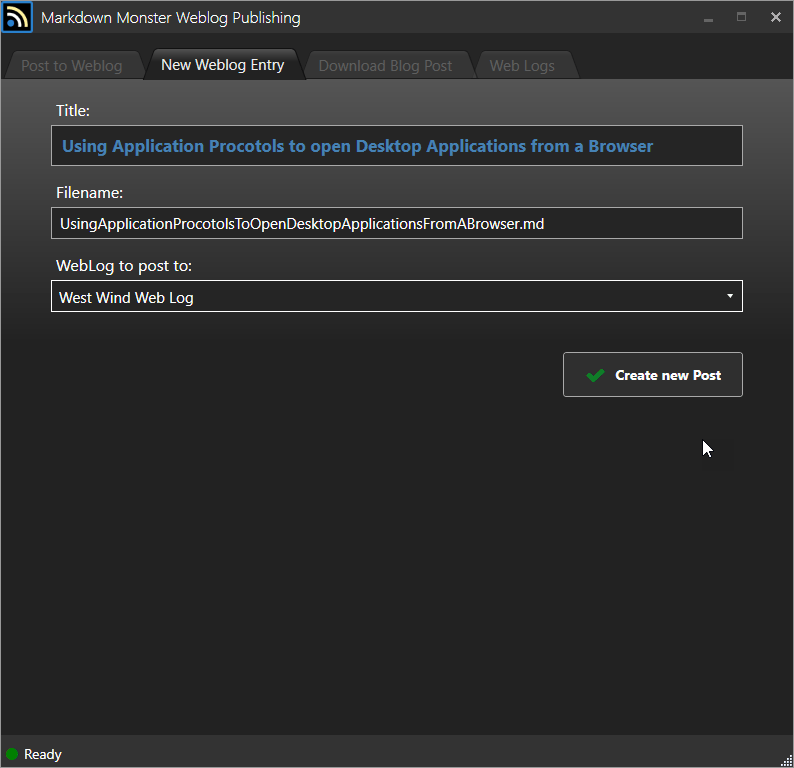
This option generates a file name from your title and creates a file on disk in a pre-configured location where Weblog posts are stored. These default to DropBox, OneDrive or the Documents folder, but the location is configurable. MM uses a Markdown Monster Weblog Posts folder with sub-folders broken down by year and month with individual posts inside of those folder. Each post has its own dedicated folder:
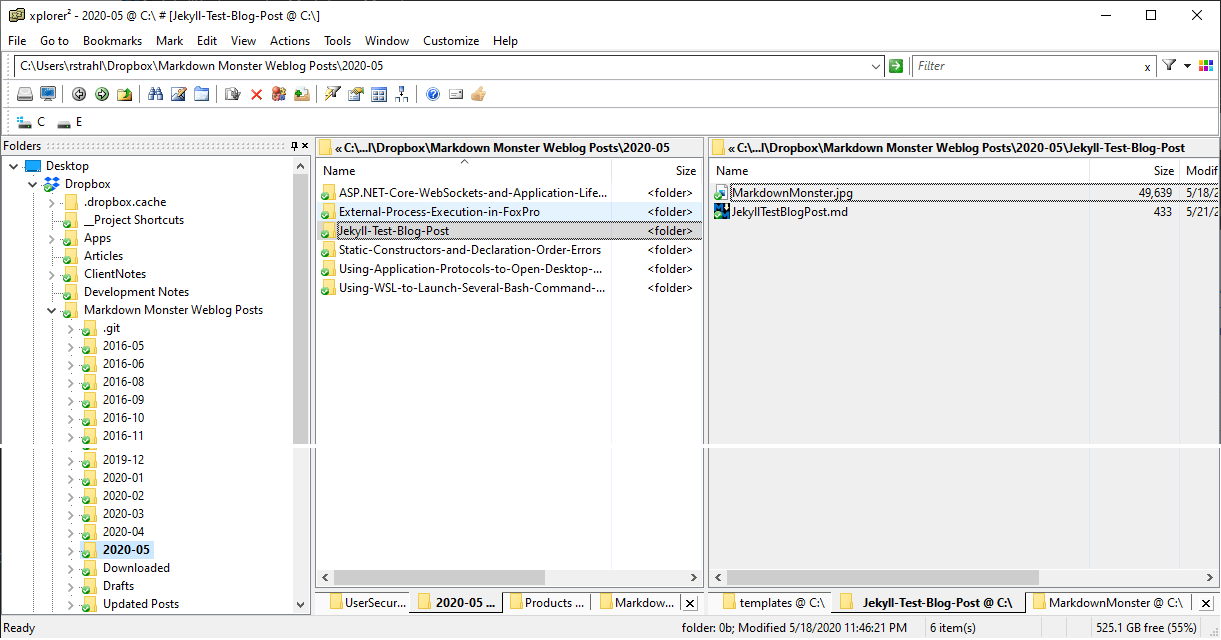
This works great to store all of your blog posts in one place. It's easy to store them in a Git repository like this, it's easy to search using the Explorer search dialog, and because the content is separated from the publishing platform and each post is self-contained it's easy to re-purpose the content for either republishing to multiple Weblogs or for migrating to a different publishing engine in the future.
This structure and the New Weblog Post flow is totally optional, but as somebody who's had to manage nearly 2000 posts over the years this has been easy to maintain and work with over the years.
Write your Content
Next - write your post in plain Markdown. There's nothing special about the markdown, nothing special you have to write or add. Although MM uses YAML metadata you don't have to add this manually - it'll be created when you publish your post and then added to the document.
One small recommendation is to use either relative links for related resources like images, or store them in a remote location like Azure Blob Storage, Imgur or a Github Image dump repository and link them as fully qualified URLs.
Set up a WebLog Configuration
Before you can publish your post to a Weblog site you need to configure the site by specifying what type of API it is using a URL or local folder to access, credentials and an optional preview URL. To access this you can use the Weblog Dialog from the toolbar button or via Weblog -> Weblog Configuration from the menu.
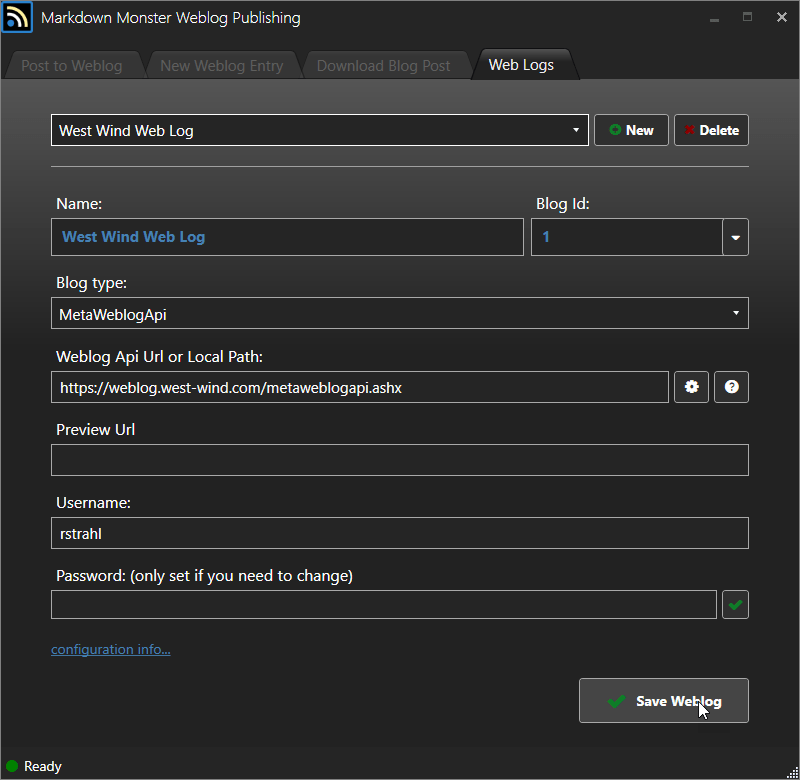
Configuration varies slightly based on the Weblog engine you're publishing to so please use the links at the top of the page to jump to your specific API used.
Publish your Weblog
Once your blog is configured you're ready to publish your first post. Click on the button in the toolbar to bring up the Post dialog and make sure you select the Web Site to post to and choose your configured site if it isn't already set.
The title is auto-filled from your content and you can provide an short paragraph as an abstract (for some blog types). Categories and Keywords are comma delimited lists of values you can provide to organize and tag your posts.
It's also possible to add custom fields to your your post data which is useful if you control the Web site code and you can run custom code to extract these custom fields on the server.
When you publish your post with Post to Weblog or you click on the Save Metadata button the post is updated with a YAML block that holds the data that is displayed in the dialog.
Note: The meta data is stripped out before your post is published to the server. It is available in the raw Markdown posted in the
custom_fields:mt_markdownfield that implicitly gets sent with each post to the server.
When the post is published the meta data is updated with a postId and permalink provided by server (if available) and MM will navigate to the URL that was received.

Comment or report problem with topic